AI as provocation rather than solution
by Kevin Bacon, Digital Manager, Brighton Museum
As part of the GIFT Action Research, we ran an experiment that showed how AI could trigger surprising interpretations of objects. This is useful as a provocation for our curation practices – a way to come up with different stories about our objects. As a bonus, the experiment provided ideas about how to develop a more audience-centric approach to digitisation.
What did you want to find out?
Whether an AI driven autotagging feature in our digital asset management system could be used to improve documentation practices by humans. The theory was that if only about 50% of these AI created tags are accurate, could the mistakes encourage the creation of new, correct data that would have not been captured had the mistake never been made?
This is based on the idea that AI may function better as a provocation rather than a solution. If the accuracy of AI is questionable, the benefits may lie in AI being able to recognise marginal elements of a visual record that a human would overlook. For instance, a curator might record the identity of a portrait subject and the date it was painted, but omit to mention the hat she wears.
What did you do?
There were three stages to the experiment:
- We invited two members of staff to write basic descriptions for a series of random objects from the collections.
- After writing the descriptions, each member of staff was asked to check the AI created tags, remove incorrect ones, and add new ones.
- Having corrected the tags, each staff member was then asked to return to the description and see if the experience of inspecting the tags would encourage them to change the descriptions.
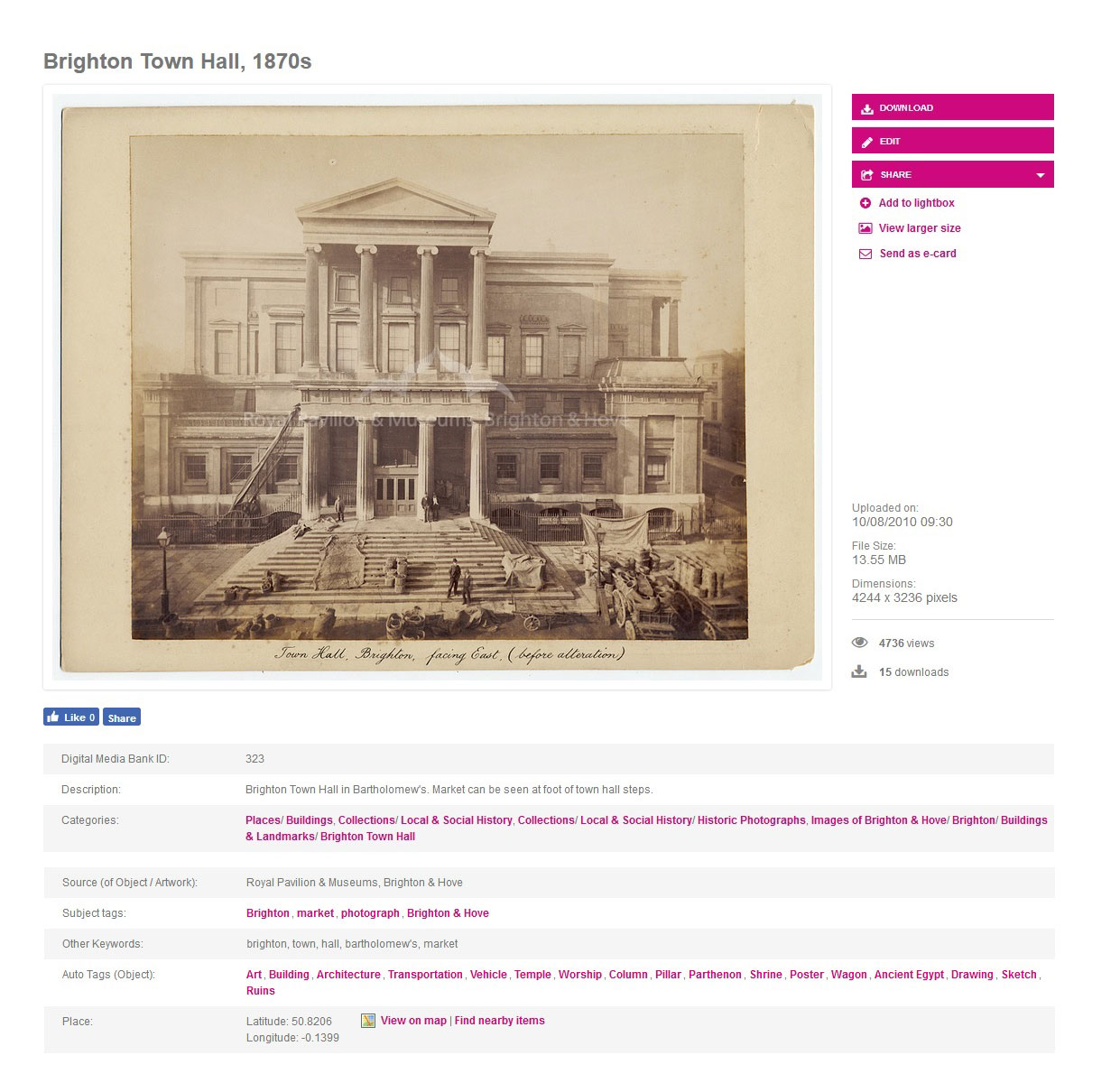
Example from our system. See the Auto Tags created by AI. @ Brighton Museum.
Was it successful?
Yes. Participants were able to follow the experiment, and the outcomes were interesting. It certainly showed that AI has the power to redirect the human gaze.
What did you learn?
We learned that correcting inaccurate data could encourage new discussions, and new ways of looking at objects. For instance, AI could identify architectural features in a local landmark that a social historian might not think to document.
As a bonus, the experiment inspired a useful conversation about how we might map the use of online collections to different audiences.
What surprised you?
We had originally planned the experiment as a lab-like, almost clinical examination of documentation behaviour. But the conversation it inspired provided some useful ideas about how to develop a more audience-centric approach to digitisation. In part, that was probably because the structure of the experiment was encouraging a rethink of who might be using this data.
In particular, a colleague with expertise in the natural sciences observed that natural science collections have two quite distinct audiences:
- scientific researchers
- artists looking for inspiration
This has encouraged a further publishing experiment. At present, we’re working to publish images of these collections with more detailed classificatory data on our online collections for scientific researchers. But we also want to use a data-lite presentation on Pinterest for artists looking for inspiration. This is the first time we’ve ever applied an audience segmentation model to the publication of collection data.
What methods or tools did you use?
On a technical level, the DAMS we use is Asset Bank, which is based on Amazon Rekognition.
What other resources did you use?
My thinking behind the experiment was influenced by reading about some of the psychology behind behavioural economics, particularly Daniel Kahneman’s ‘Thinking Fast and Slow’ (2011). That might seem like a long way from museum practice, but some of the heuristics identified by this research, which can lead to cognitive biases and plain errors in judgements, are really relevant.
In particular the phenomenon of WYSIATI (‘What You See Is All There Is’: a focus illusion that tends to blind people to the surrounding context of a problem) could help explain why museum documentation practices can be good at creating structured data that describes the inherent attributes of objects, but are exceedingly poor at creating data that is meaningful to non-curatorial users. (Perhaps we need a ‘behavioural museology’?).
For example, museums will invest a lot of money in creating databases that allow users to search for objects from a fashion collection that were made between 1837 and 1901, but won’t provide any meaningful data for a teacher searching for a ‘Victorian dress’.